Ipek Erdogan

Data scientist, trying to be a MSc Computer Engineer. Looks forward to artificial intelligence taking over the world (JK).
Even if I couldn't upload the major ones (Bachelor's Thesis, Master's Thesis, and job-related codes) due to confidentiality, you may still see some of my small projects here.
View my LinkedIn profile
View my Github profile
Mail me!
Convolutional Neural Network(CNN) from Scratch
In this project, I implemented a three-layered convolutional neural network (CNN) (that was the constrained) architecture using a deep learning library (PyTorch). For the training and testing phases, I used CIFAR10 dataset.
For the full pipeline:
1. Starting with a Base Model
I have started with a base model, which has three convolutional layers followed by max-pooling layers and there were 2 fully connected layers at the end. This model made me start with 63% accuracy in both training and testing. Then I tried to change the kernel sizes of these convolutional layers but it didn’t effected results that much. I decided to add Batch Normalization between the convolutional layers and activation functions. This resulted with improvement in training and testing accuracies.
Then I made data augmentation with ”Random Cropping” yet it decreased model’s performance. That’s probably because there were no overfitting, the model haven’t learn well yet. Improving generalization ended up with underfitting. Also, at this point, I have realized that adding max pooling layer after all of the convolutional layers may cause underfitting, too.
2. Trying Different Approaches
Since max-pooling layer undersamples it’s inputs, I decided to remove one of the max-pooling layers (let’s call it Model 2). I had a much better result. I also wanted to add ”Random Vertical Flip” which ended up with again, bad results. So I removed it and also I have changed the first convolutional layer’s kernel size. Again, my model’s performance was not good enough. I tried to remove the second max-pooling layer too, and changed the second convolutional layer’s kernel size. Still, results were not better. So I decided to go back to my best models architecture (Model 2) but I also removed the second max-pooling layer and add a second fully connected layer. This brought me to my best model with the best results.
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 6, 3)
self.batch1 = nn.BatchNorm2d(6)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 10, 3)
self.batch2 = nn.BatchNorm2d(10)
self.conv3 = nn.Conv2d(10, 16, 3)
self.batch3 = nn.BatchNorm2d(16)
self.fc1 = nn.Linear(16 * 13 * 13,256)
self.fc2 = nn.Linear(256, 32)
self.fc3 = nn.Linear(32,10)
def forward(self, x):
x = F.relu(self.batch1(self.conv1(x)))
x = F.relu(self.batch2(self.conv2(x)))
x = self.pool(F.relu(self.batch3(self.conv3(x))))
flattens = torch.flatten(x, 1) # flatten all dimensions except batch
x = F.relu(self.fc1(flattens))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x,flattens
Adding one more fully connected layer probably prevented information loss. The dimension difference were high in between the input and output of the fully connected layers, when I was using 2 FC. I used the module down below for the evaluation part.
def eval(net,testloader):
batch_losses = []
correct = 0
net.eval()
criterion = nn.CrossEntropyLoss()
total_size=0
with torch.no_grad():
for i, data in enumerate(testloader, 0):
inputs, labels = data
total_size += labels.size(0)
outputs , flattens = net(inputs)
flattens = flattens.detach().numpy()
if (i==0):
total_flatten = flattens
total_labels = labels
else:
total_flatten = np.concatenate((total_flatten, flattens), axis=0)
total_labels = np.concatenate((total_labels, labels), axis=0)
loss = criterion(outputs, labels)
batch_loss = loss.item()
batch_losses.append(batch_loss)
l_outputs = np.argmax(outputs.detach().numpy(), axis=1)
correct += np.sum(l_outputs == labels.detach().numpy())
acc = 100 * correct / total_size
total_loss = sum(batch_losses) / len(batch_losses)
return total_flatten, total_labels, total_loss,acc
3. Results
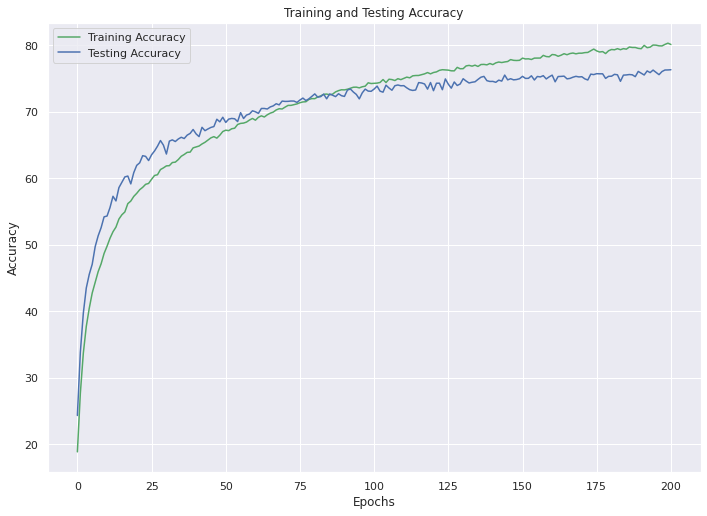
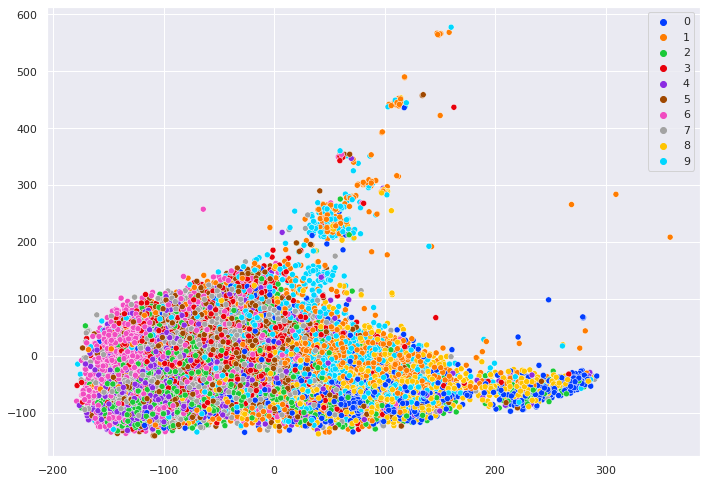
I ran the model during 200 epochs and tried three different optimizers: Adam, RMSprop and SGD. I tried all of them and finally decided to use SGD since it performed the best. You can check the loss and accuracy graphs and the tsne plotting of the embeddings down below. Normally, I would expect tSNE plot to be more sparsed with the accuracy I got. It may be because my latent representation dimension was high (2704) or my tSNE function’s iteration parameter was not high enough.
Epoch Accuracy: 80.13
Epoch Loss: 0.56495221397456
Epoch Test Accuracy: 76.33
Epoch Test Loss: 0.7284866685320617